Answer
Puzzler 1
PyTorch has a very high launch overhead, as is reflected by the gaps in the trace below.
 PyTorch Overhead
PyTorch Overhead
The table shows the operator level breakdown for split_stack. These calls cumulatively take 188
us, but the total time on GPU, start-to-finish is 1613 us because of the CPU side launch overhead.
| Operator | Count | Time (microseconds) |
|---|---|---|
| Layer Norm | 16 | 6 |
| Tanh | 16 | 4 |
| Cat | 1 | 13 |
| Copy | 1 | 4 |
| Linear | 1 | 8 |
| Relu | 1 | 3 |
In contrast, combined makes just 5 calls that collectively take 66 us. The total time is 198 us,
because of the kernel launch overhead. Note that there’s almost no gap between layer norm and tanh.
This is because layer norm takes long enough to perform that it hides the CPU-side launch overhead.
 Minimal Launch Overhead
Minimal Launch Overhead
It’s interesting that layer norm in combined takes 43 us, which is roughly 7.1 times slower
than in each individual layer norm in split_stack, even though layer norm in split_stack takes
16 times more data. The reason is that the smaller calls to layer norm do not saturate the GPU
computationally. The same phenomenon is seen in tanh, where it’s even more pronounced. As discussed in
Counting TFLOPS, tanh has low arithmetic
intensity and is therefore memory bandwidth limited (this is true for almost every point-wise
kernel); the same is true for layer norm.
Puzzler 2
compiled_split_stack makes 19 kernels calls. Fewer kernels means less kernel launch overhead and
is one of the reasons for the speedup.
 compiled_split_stack trace
compiled_split_stack trace
The first 16 are to kernels that are a fusion of layer norm and tanh, and take 5 us each, which is
less than the 10 us layer norm and tanh together take in unfused. PyTorch 2 compilation combines
layer norm and tanh, which reduces the memory bandwidth needed to perform these two operations by
half. The resulting computation is still memory bandwidth limited - this is why the compiled fused
kernel takes half the time. This is responsible for the rest of the speedup of
compiled_split_stack relative to split_stack. A similar situation holds for the stack and Relu
operations.
compiled_combined has four kernels that perform the layer norm, tanh, linear, and Relu. They take
a total time of 26 us.
 compiled_combined trace
compiled_combined trace
Recall that layer norm alone took 44 us in combined, further evidence of the power of the Triton
backend that is used in PyTorch 2.
Discussion
What is the significance of these puzzlers?
The computation being performed in the code above is very commonly seen in recommendation systems - we lookup features from embedding tables and then apply layer norm, tanh, etc. on individual slices. Though it’s easier to understand the computation as taking place on individual slices, because the number of embedding tables is large, it’s more efficient from a computational perspective to avoid working on individual slices. See this blog post for more details.
What’s the difference between horizontal and vertical fusion?
Horizontal fusion is when we group logically independent tensors into a single tensor and apply
operations on the single tensor. It’s done to reduce kernel launch overhead as well as get better
GPU utilization. The combined function in Puzzler 1 shows horizontal fusion.
Vertical fusion is when
we combine kernels where one kernel writes output tensors that are input to another - this is done
to reduce the memory bandwidth needed. See the figure below for a graphical illustration - note that
Read-Write bandwidth is reduced by a third. The compiled versions of split_stack and combined
perform vertical fusion.
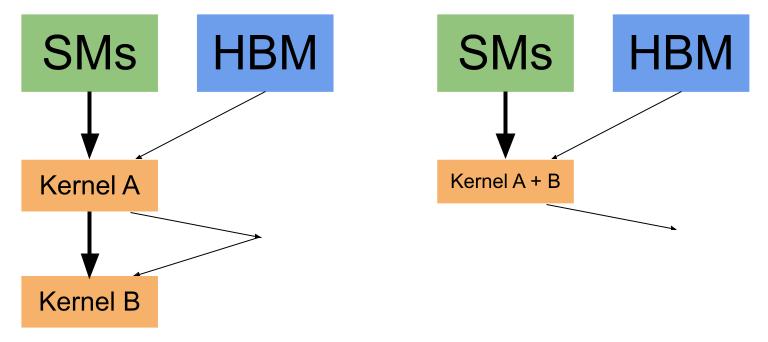 Vertical Fusion Illustration
Vertical Fusion Illustration
Can we combine horizontal and vertical fusion?
Yes! This is exactly what compiled_combined is doing.
How does vertical fusion work under the hood?
torch.compile uses torch.inductor and Triton
- Torch Inductor is a new compiler for PyTorch, which is able to represent all of PyTorch and is built in a general way such that it will be able to support training and multiple backend targets.
- Triton is a new programming language that provides much higher productivity than CUDA, but with the ability to beat the performance of highly optimized libraries like cuDNN with clean and simple code. It is developed by Philippe Tillet in his PhD research at Harvard, and is seeing wide adoption and traction across the industry.
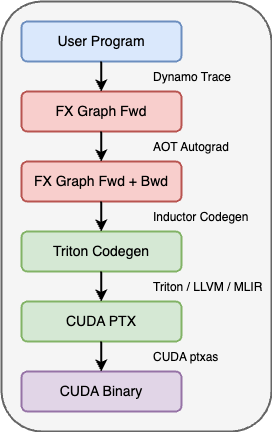
PyTorch 2 Compilation Flow
In our example, the maximum element-wise difference between compiled_fused and unfused on random inputs was of the order of 1e-7. Why do the values differ?
- Vertical fusion can change numerics, because the code may perform operations in a different order, and finite-precision arithmetic is not associative (though it is commutative). For example, (0.1 + 0.2) + 0.3 differs from 0.1 + (0.2 + 0.3) by ~1e-16. The net effect of the noise introduced by finite precision arithmetic depends on the compute graph and inputs.
- Incidentally, horizontal fusion does not change numerics (assuming the underlying kernels are deterministic, which is not always the case).
Can fusion reduce performance?
Yes, because fusion can lead to caching becoming less effective, and registers having to be continually saved and re-loaded (this is known as spillage).
Are CUDA Graphs a form of fusion?
No, the number of kernels called is unchanged. The difference is that CUDA Graphs removes the need for the PyTorch dispatcher through the use of record and replay. This does away with the dispatch overhead. It also does static allocation of buffers, which can also help performance by avoiding calling out to the CUDA Caching Allocator.
Why don’t we use torch.compile() universally?
- It is a new feature, and not all bugs have been worked out, especially in the context of distributed.
- It can lead to slowdowns because of added time to compile.
- It can lead to OOMs because of increased memory usage.
- Depending on the function being implemented, as well as the shapes involved, Triton kernels can actually be slower than the native PyTorch ones.
- It does not support dynamic shapes.
- It is very easy to write code that keeps torch.compile() from performing fusion, e.g., logging
shapes at the start of the iteration
split_stackwill keep torch.compile() from any kind of optimization. - torch.compile() doesn’t automatically perform horizontal fusion.
Where can I learn more about torch.compile()?
See this blog for a detailed explanation.
What should you remember in years to come?
Fusing operations can lead to significant performance gains - through improving arithmetic intensity and reducing launch overhead.